
Mean Reciprocal Rank
Metric for search relevancy

Mean Reciprocal Rank (MRR) is a statistical measure widely used to evaluate the effectiveness of search engines, question-answering systems, and recommender models. It measures the average of the reciprocal ranks of the first relevant result in a list of ranked responses. The reciprocal rank is the multiplicative inverse of the rank of the first correct answer.
Here's the formula for MRR:
MRR = (1 / Q) * Σ (1 / rank_i) where Q is the total number of queries, and rank_i is the rank of the first relevant result for the ith query.
Example:
Imagine we have a search engine that returns the following ranked results for three different queries:
Query 1: [irrelevant, relevant, irrelevant, relevant]
Query 2: [relevant, irrelevant, irrelevant, irrelevant]
Query 3: [irrelevant, irrelevant, relevant, irrelevant]
The reciprocal ranks for each query are:
1. Query 1: The first relevant result is at position 2, so the reciprocal rank is 1/2 = 0.5
2. Query 2: The first relevant result is at position 1, so the reciprocal rank is 1/1 = 1.0
3. Query 3: The first relevant result is at position 3, so the reciprocal rank is 1/3 ≈ 0.333
Now, we can calculate the Mean Reciprocal Rank:
MRR = (1 / 3) * (0.5 + 1.0 + 0.333) ≈ 0.611
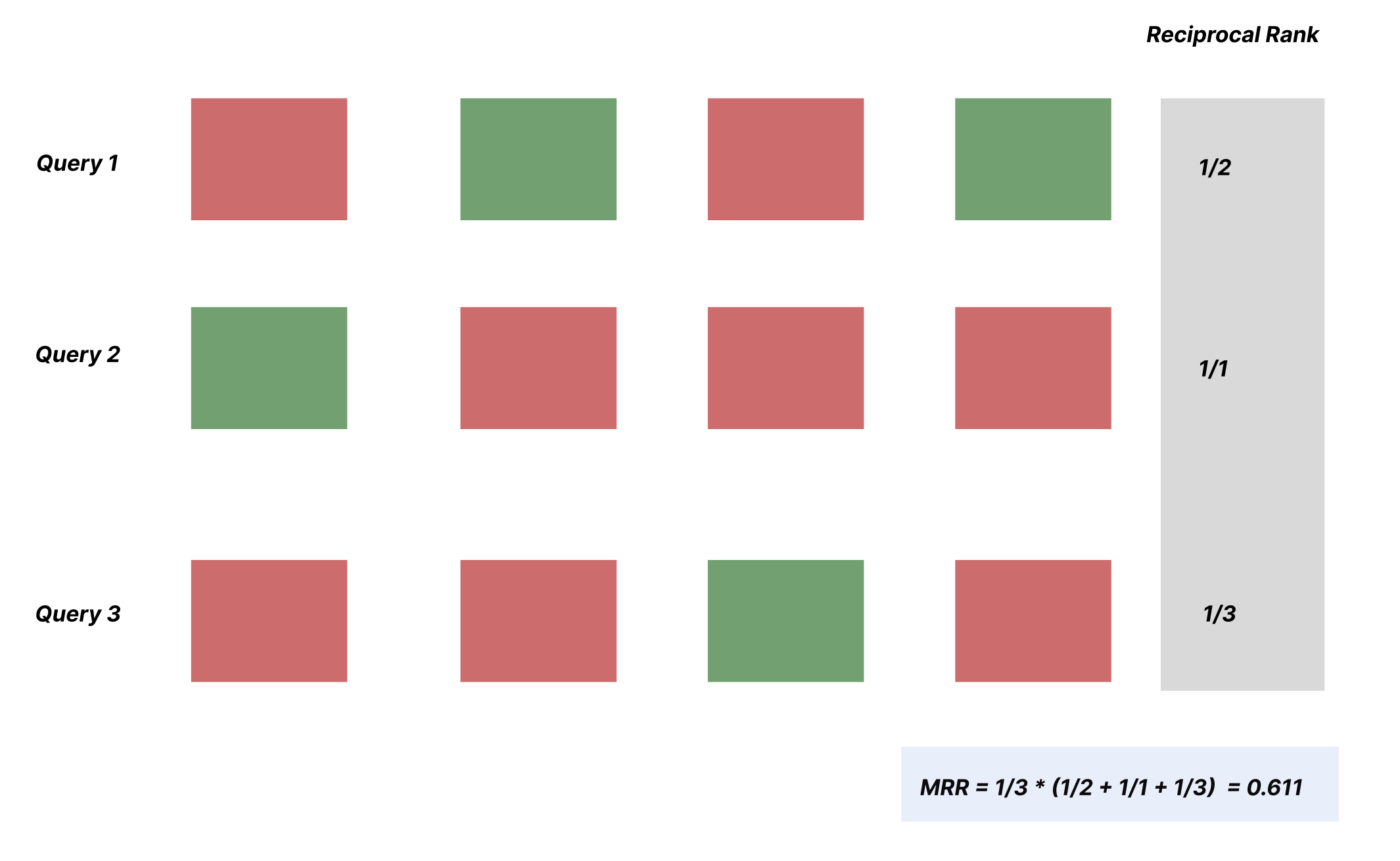
In this example, the MRR is approximately 0.611, which means that on average, the search engine returns a relevant result within the top 1.63 (1/0.611) positions.
Though MRR is an intuitive metric, it’s important to understand its limitations
Insensitivity to rank distribution: MRR only considers the rank of the first correct answer, ignoring the distribution of other relevant items in the ranked list. This means that the metric may not capture the system's overall performance when there are multiple relevant items.
Binary relevance assumption: MRR assumes that items are either relevant or not relevant, without considering the varying degrees of relevance. This can be limiting when evaluating systems that deal with items of diverse relevance levels.
Lack of interpretability: MRR scores can be difficult to interpret and compare, as the metric does not have an intuitive scale. A higher MRR score indicates better performance, but the difference between two scores may not be easily interpretable in terms of system quality.
Not considering result set size: MRR does not account for the size of the result set returned by the system. A system that retrieves a small result set with a relevant item at the top may have a better MRR than a system that retrieves a larger result set with several relevant items at lower ranks.
There are several other metrics frequently used such as Normalized Discounted Cumulative Gain (NDCG), Average Precision, Precision@k etc. I will be covering these in the upcoming blogs.